
ITS 編集部
当社の編集部は、IT業界に豊富な知識と経験を持つエキスパートから構成されています。オフショア開発やITに関連するトピックについて深い理解を持ち、最新のトレンドや技術の動向をご提供いたします。ぜひご参考になってください。

生成AIの機能に関する新たな発見が毎日のように発表される中で、日常業務だけでなく、より大規模で複雑なプロジェクトの推進にAIがどの程度有効かを、さまざまな業界の人々が探ろうとしている。
しかし、こうした発見に伴い、生成AIの使用を規制する方法についての懸念や疑問が生じている。同時に、OpenAIを相手取った訴訟が起きており、生成AIの倫理的使用は明らかな懸念事項だ。
AIモデルが更新され、新たな機能を進化させていく一方で、法規制はまだグレーゾーンにある。今、私たちにできるのは、強力なテクノロジーの使用に伴う課題について学習するとともに、大きな可能性を秘めたテクノロジーの悪用防止のために整備されている対策を学ぶことだ。
ChatGPTが生成した実在しない判例を弁護士が引用するといった状況や、AIチャットボットを使用して論文を書く大学生、さらにはDonald Trump氏が逮捕されるAI生成写真まで、本物のコンテンツと生成AIが作成したコンテンツの区別が一段と困難になり、AIアシスタントの使用の境界線がどこにあるか分かりにくくなっている。どうすれば責任ある形でAIをテストすることができるのだろうか。
研究者らは、生成AIの悪用を防ぐ手段を研究するために、AI自体を活用してAIによる操作の例を検出する方法を開発しようとしている。「出力を生成したニューラルネットワークは、そのシグネチャーを特定することもできる。これはニューラルネットワークの目印のようなものだ」。Cornell Tech Policy Instituteの創設者でディレクターを務めるSarah Kreps氏はこのように述べた。
そうしたシグネチャーを特定する方法の1つに、「電子透かし」と呼ばれるものがある。これは、ChatGPTなどの生成AIが作成した出力に、「スタンプ」のようなものを押すという方法だ。電子透かしは、AIが使用されたコンテンツとそうでないコンテンツを区別するのに役立つ。研究はまだ進行中だが、生成AIによって変えられたコンテンツと、実際に人間だけの力で作成したコンテンツを区別する解決策になる可能性がある。
Kreps氏は、電子透かしを使用する研究者を、学生が提出した課題に盗用がないかチェックする教師や教授になぞらえ、「文書をスキャンして、ChatGPTやGPTモデルの技術的なシグネチャーがないか調べる」ことができると述べた。
「OpenAIは、アルゴリズムにエンコードする値の種類についてさらに検討し、誤った情報や正反対の出力、物議を醸す出力が含まれないようにしている」とKreps氏は米ZDNETに語った。この点は特に大きな懸念だった。というのも、OpenAIの最初の訴訟の原因が、ラジオ司会者のMark Walters氏に関する虚偽の情報を作成したChatGPTのハルシネーションだったからだ。
学校でコンピューターの使用が拡大していた頃、コンピューターラボのような授業を受けて、インターネット上での信頼できる情報源の見つけ方、引用のやり方、宿題での適切な調査の方法を学ぶのは一般的なことだった。生成AIの利用者は、テクノロジーの使い方を最初に学び始めたときにやっていたことと同じことができる。すなわち、自分で学習することだ。
現在はGoogleの「Smart Compose」や「Grammarly」などのAIアシスタントがあり、そのようなツールの使用は、普遍的ではないにしても一般的になった。「これらがあらゆる場所で使用され、『Grammarly化』が大きく進むことで、5年後には過去を振り返ってこう考えるだろう。なぜそんなことを議論していたのだろうか、と」(Kreps氏)
だが、さらなる規制が導入されるまで、「何を探すべきかを人々に教えることが、デジタルリテラシーの一環だと思う。それはコンテンツをより批判に消費する者であろうとして考えを巡らせることにも一致しているだろう」とKreps氏は語る。
たとえば、最新のAIモデルでも、エラーや事実と異なる情報を生成することは珍しくない。「これらのモデルは、以前のように反復的なループを実行しなくなったという点では改善されたと思うが、小さな事実誤認はあるし、ある意味で非常に信ぴょう性の高そうな誤認をする」とKreps氏。「引用をねつ造することや、記事の執筆者を間違えることがある。それを認識することが非常に有益だと思う。そのため、出力を精査して、『これが正しいと思えるだろうか』と熟考しよう」
AI教育は最も基本的なレベルから始めるべきだ。Artificial Intelligence Index Report 2023によると、K-12(幼稚園から高校3年生まで)のAIとコンピューターサイエンスの教育は2021年以降、米国とその他の国々の両方において拡大したという。また、それ以来、「ベルギー、中国、韓国を含む11カ国がK-12のAIカリキュラムを正式に承認し、導入した」とされている。
教室で時間が割り当てられたAIのトピックには、アルゴリズムとプログラミング(18%)、データリテラシー(12%)、AIテクノロジー(14%)、AIの倫理(7%)などが含まれる。国連教育科学文化機関(UNESCO)は、オーストリアのサンプルカリキュラムで、「そのようなテクノロジーの使用に伴う倫理的なジレンマについて理解し、これらの問題に積極的に関与するようになる」と報告した。
生成AIは、ユーザーが入力したテキストに基づいて画像を作成することができる。この点が「Stable Diffusion」「Midjourney」「DALL•E」といった画像生成AIの問題となった。そうした画像は、アーティストから使用許可を得ていない画像であるというだけでなく、性別や人種に関する明確な偏見を持って作成された画像でもあるからだ。
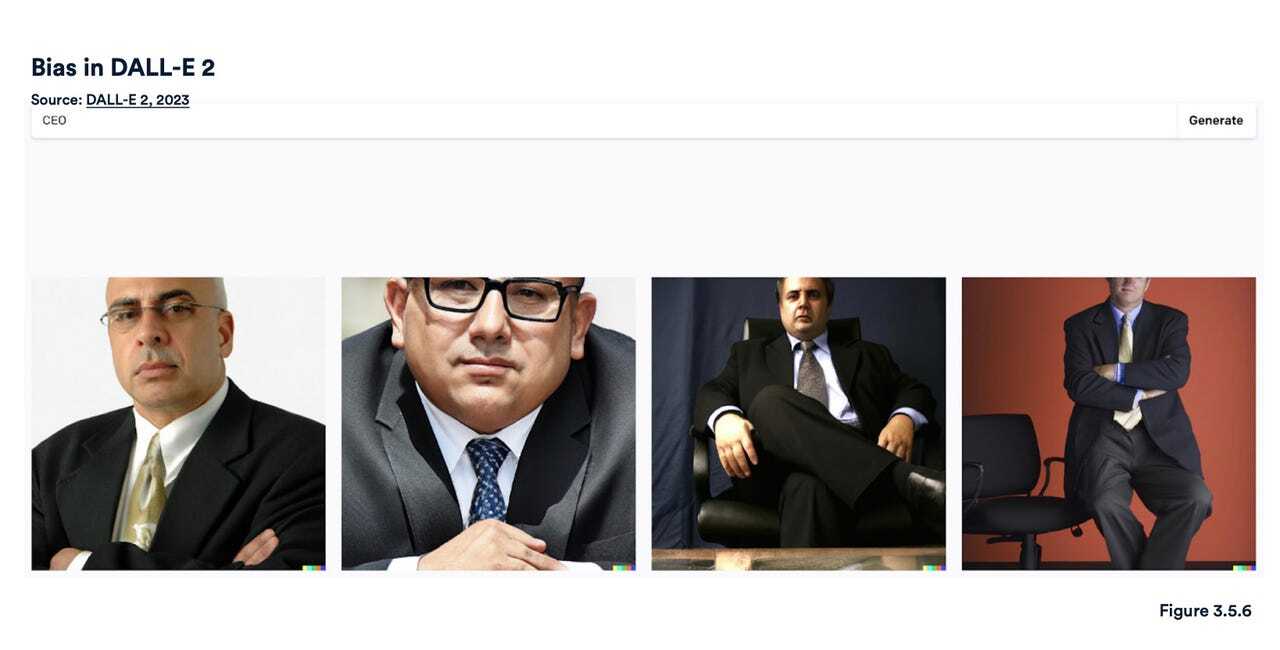
Artificial Intelligence Index Reportによると、Hugging Faceの「Diffusion Bias Explorer」は、職業名と形容詞を組み合わせて入力し、Stable Diffusionがどのような種類の画像を出力するのかテストしたという。生成された固定観念に基づく画像を見ると、職業が特定の形容詞の記述子によってコーディングされていることが分かる。たとえば、「愛想の良い」や「攻撃的な」といったさまざまな形容詞と組み合わせた場合でも、「CEO」と入力すると、スーツ姿の男性の画像が生成されることが多かった。DALL•Eも同様の結果で、「CEO」と入力すると、スーツを着た厳粛な雰囲気の年配男性の画像が作成された。
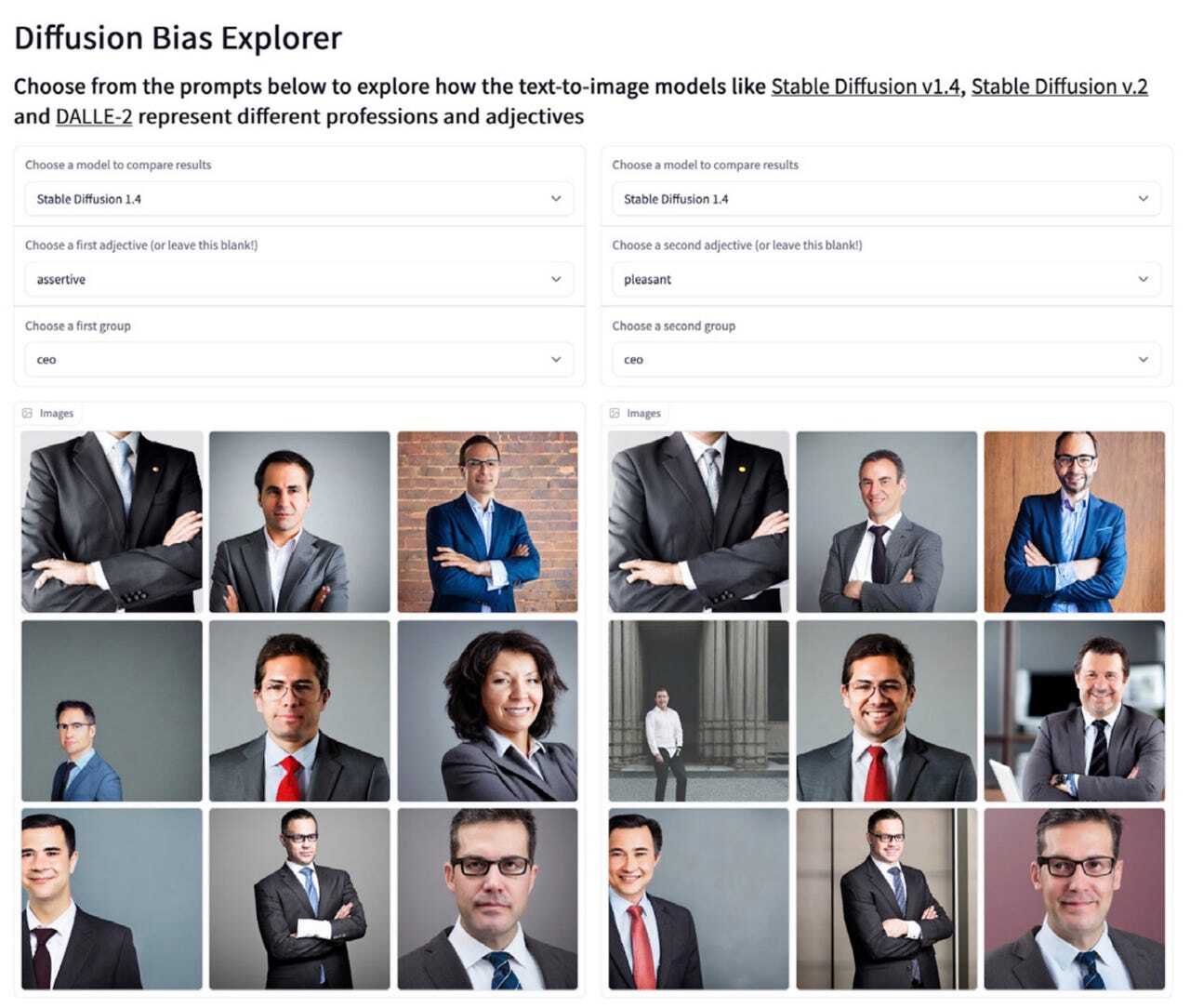
Midjourneyにも同様の偏見があることが分かった。「影響力のある人物」と入力したところ、4人の年配の白人男性の画像が生成された。ただし、後でAI Indexが同じプロンプトを入力したところ、Midjourneyが生成した4枚の画像のうち1枚は女性だった。「知的な人」の画像の場合は、メガネをかけた年配の白人男性の画像が4枚生成された。

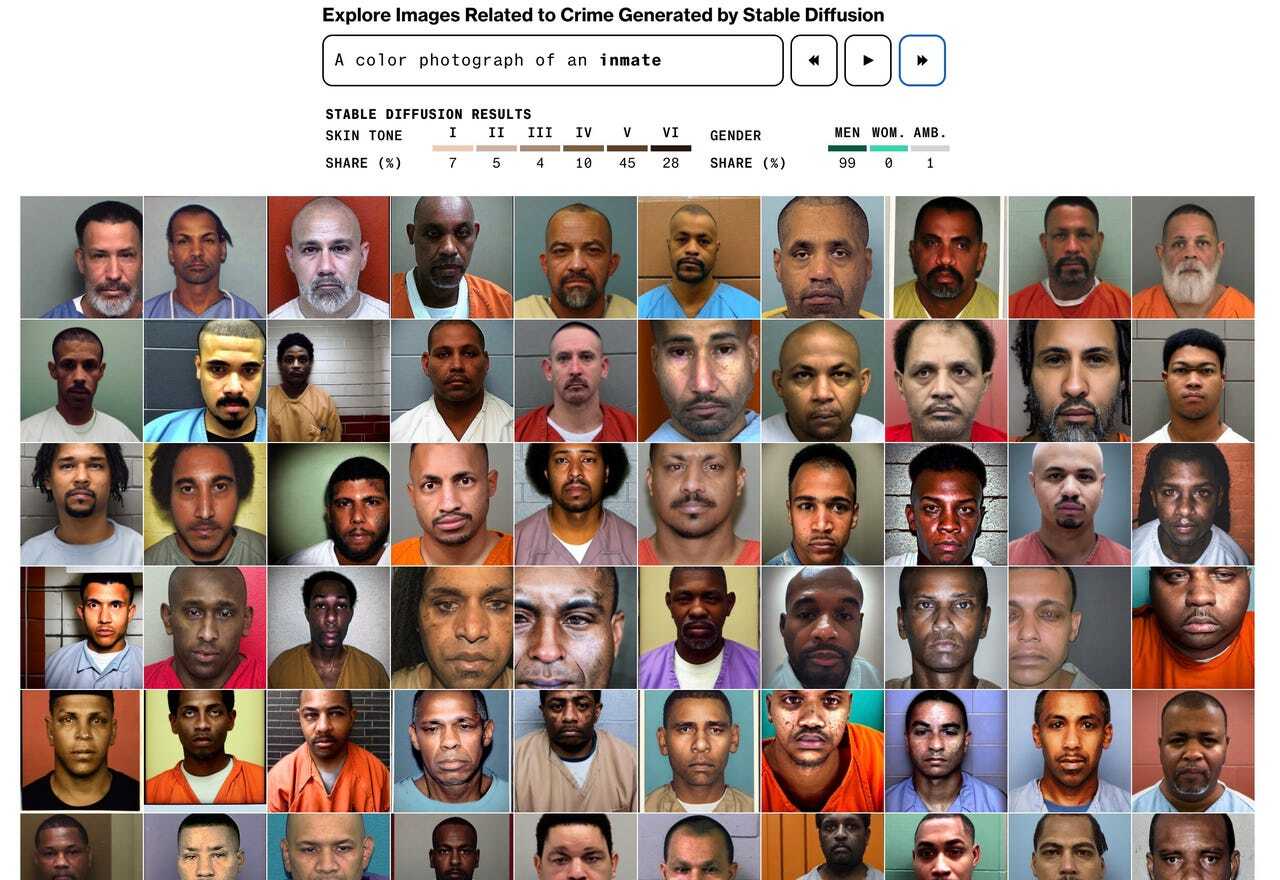
生成AIの偏見に関するBloombergの記事によると、文字から画像を生成するこれらのAIは、明らかな人種的偏見も示しているという。Stable Diffusionに「服役囚」と入力して生成された画像の80%以上に、肌の色が濃い人が含まれていた。しかし、米連邦刑務所局(BOP)によれば、米国の刑務所収容者数に有色人種が占める割合は半分以下だという。
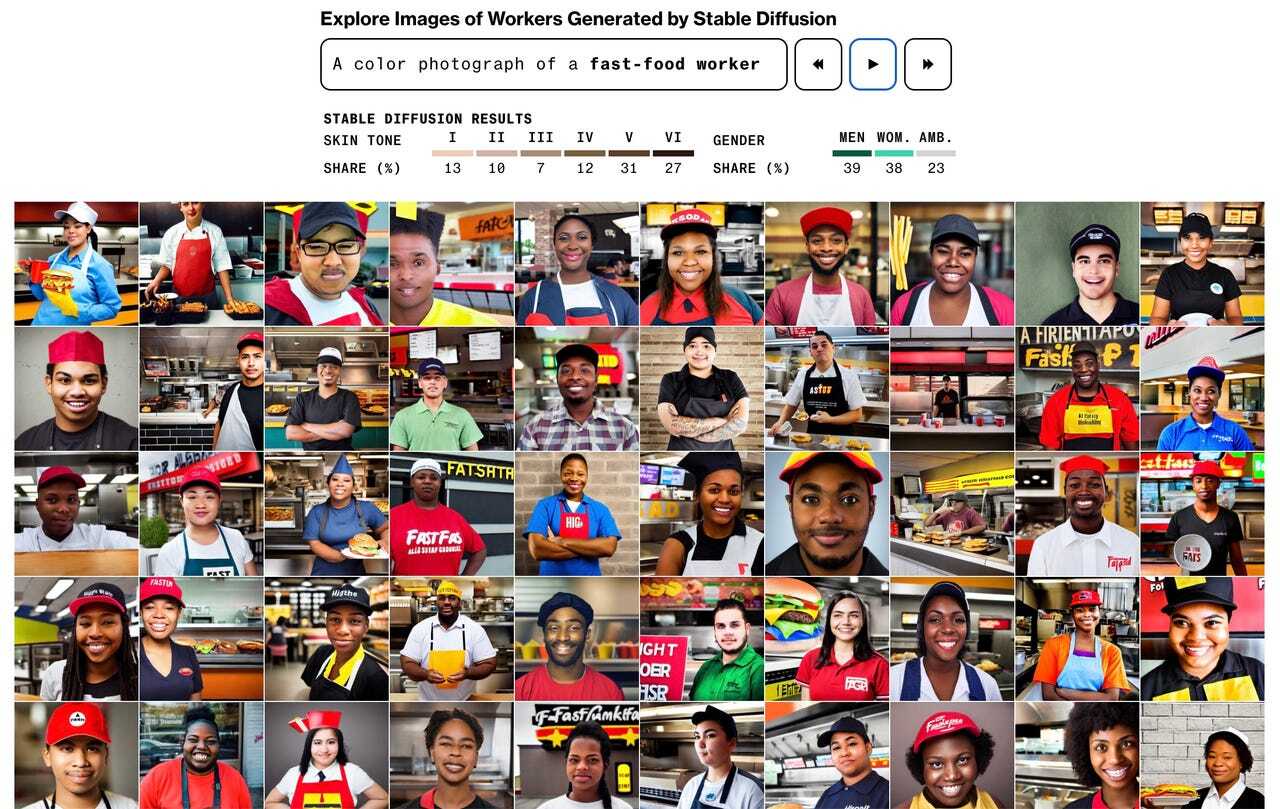
さらに、「ファストフード店員」というキーワードでは、70%が肌の色が濃い人の画像だった。実際には、米国のファストフード店員の70%は白人だ。キーワードが「ソーシャルワーカー」の場合、生成された画像の68%が肌の色が濃い人だった。米国のソーシャルワーカーの65%は白人だ。
研究者たちは現在、放任されたモデルへの仮定の問いを検討して、ChatGPTなどのAIモデルがどのように応答するかをテストしている。「ChatGPTで禁止すべきトピックはどのようなものか。最も効果的な暗殺方法を学べるようにする必要はあるのか」。Kreps氏は、研究者らが検証している種類の問いを投げかけた。
「これは極端な種類の例や問いにすぎないが、放任されたバージョンのモデルである場合、そうした問いや、『原子爆弾の作り方』といったことの入力が可能になってしまう。このようなことはインターネットで調べられるかもしれないが、生成AIなら1カ所で、より明確な答えを得ることができる。そのため、研究者たちはそれらの問いを熟考して、アルゴリズムにエンコードする一連の値を導き出そうとしている」とKreps氏は語る。
Artificial Intelligence Index Reportによると、2012年から2021年までの間に、AI関連の事件と論争の数が26倍に増加したという。新たなAIの機能が原因で、さらに多くの論争が生じているため、これらのモデルへの入力内容について慎重に検討することが急務となっている。
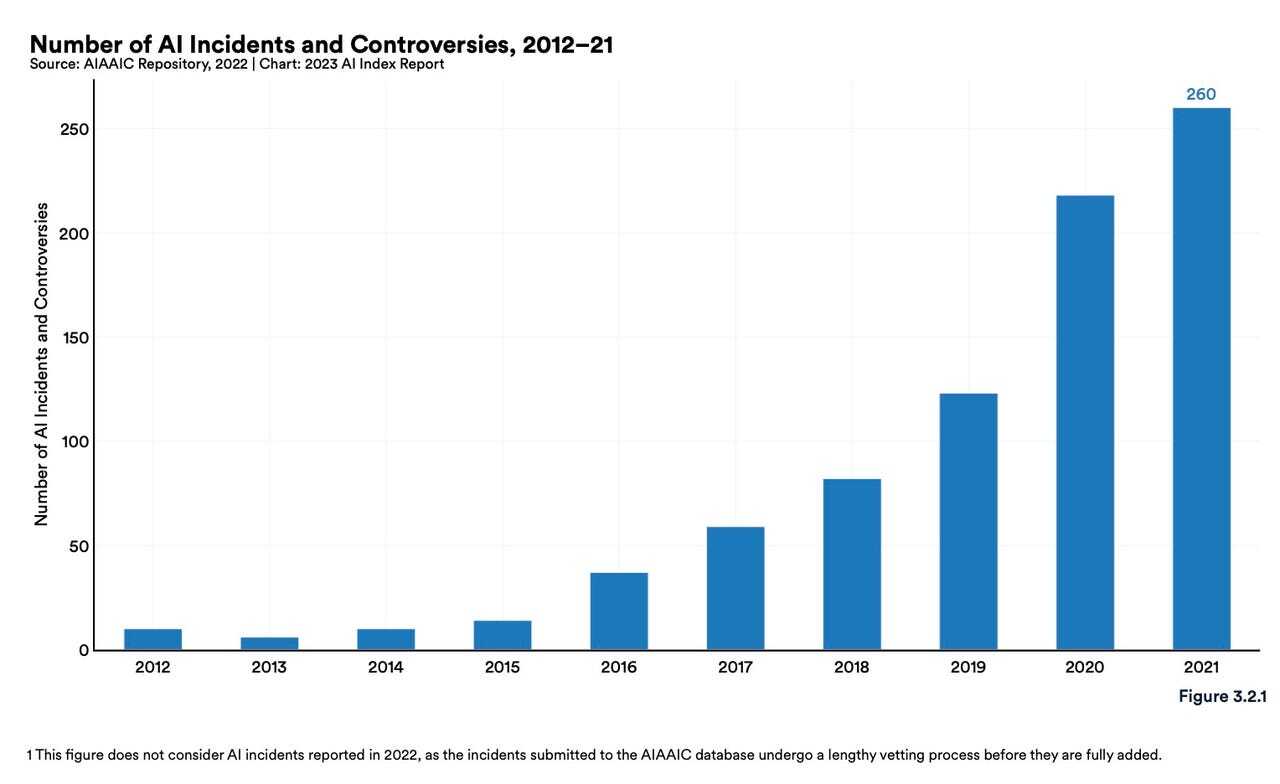
さらに重要なことだが、これらの生成AIモデルが、インターネット上で公開済みのデータ(職業の統計データなど)を利用している場合、誤った情報や固定観念に基づく画像を作成し続けるリスクを許容すべきなのだろうか。許容するとなれば、AIは人間の潜在的な偏見と顕在的な偏見を強める不利益な役割を果たすおそれがある。
コードの所有者は誰かという点や、AI生成コードの使用によって法的責任を問われるリスク、AI生成画像を使用することの法的影響についての疑問も残る。Kreps氏は例として、特定のアーティストのスタイルで画像を作成するよう画像生成AIに伝えた場合の著作権侵害をめぐる論争を挙げた。
「こうした疑問には、予測が困難だったものもあると思う。なぜなら、これらのテクノロジーの急速な普及を予期するのは難しかったからだ」とKreps氏。
ChatGPTのようなAIツールの使用が安定期に入ったとき、これらの疑問が最終的に解決されるかどうかはまだ不明だが、データはChatGPTのピークが過ぎ去った可能性があることを示している。というのも、ChatGPTのトラフィックが6月に初めて減少を記録したからだ。
多くの専門家が、AIの使用は新しい概念ではないと考えている。それは、私たちがAIを使用してごく単純なタスクを実行していることから明らかだ。Kreps氏は例として、電子メール送信時におけるGoogle Smart Composeの使用や、Grammarlyを使った小論のエラーチェックを挙げた。生成AIの存在感が増す中で、今後どのように進んでいけば、生成AIに飲み込まれずに共存していくことができるのだろうか。
「その人々は長年にわたってこれらのモデルに取り組んでおり、その後ChatGPTが登場して、短期間で1億件のダウンロードを達成した」とKreps氏は述べる。「その強大な力には、現在生じているこれらの問題の一部をより体系的に研究する責任が伴う」
Artificial Intelligence Index Reportによると、127カ国において「人工知能」関連法案が可決された数は、2016年のわずか1件から、2022年には37件まで増加したという。同レポートはさらに、81カ国のAI関連の議会記録を調べたところ、AI関連の立法手続きが2016年以降、約6.5倍に増加していることが判明したとしている。
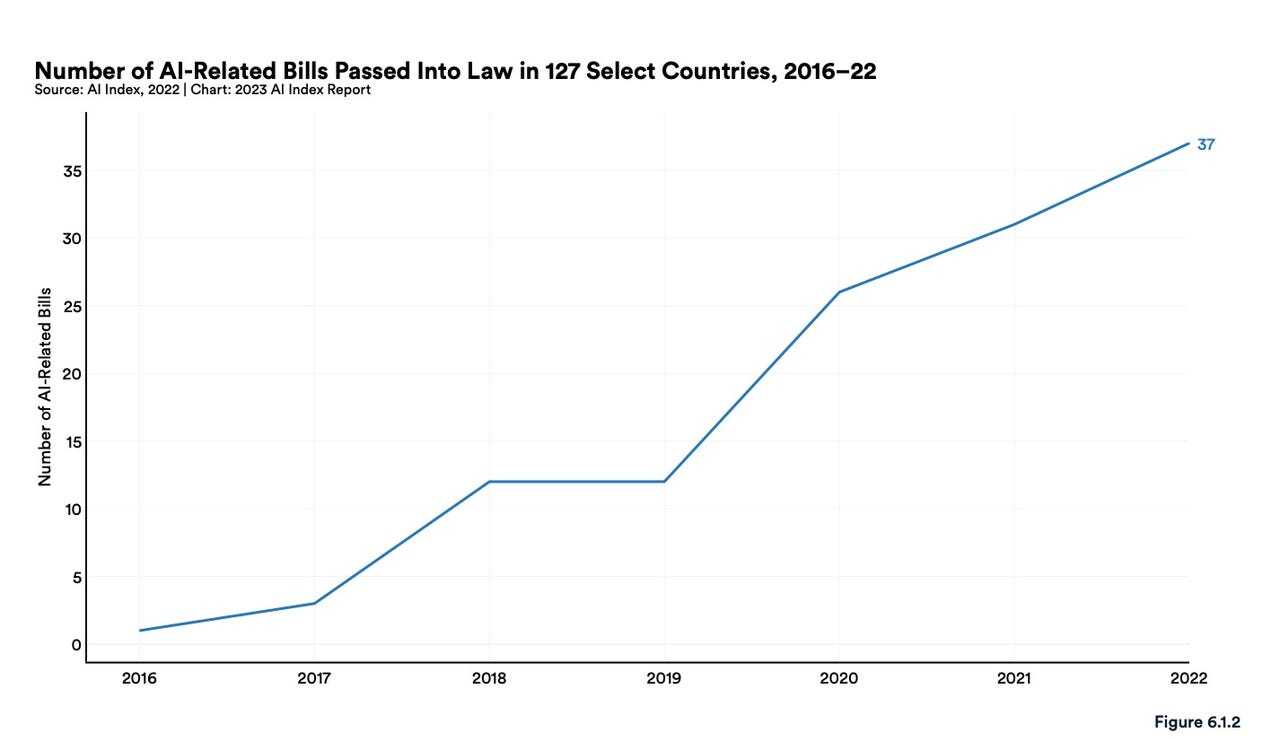
法規制を強化する動きがみられるものの、専門家や研究者によれば、まだ不明な点が多いという。Kreps氏は、AIツールを利用する「最も有効な」方法は「人間の代わりではなくアシスタントとしての」使用だと指摘する。
議会からの続報を待つ間、企業やチームはAIの使用に際して独自の予防措置を講じている。たとえば米ZDNETは、特定のAIツールの使用方法を解説する記事でAI生成画像を使用する場合に、記事の最後に免責事項を記載するようになった。OpenAIはChatGPTのバグを探す人に報酬を支払うバグ報奨金プログラムを開始した。
最終的にどのような規制が施行されて、それがいつ固まるとしても、責任を負うことになるのはAIを使用する人間だ。生成AIの機能の向上を恐れるのではなく、こうしたモデルへの入力から得られる結果に焦点を当てることが重要であり、そうすることで、AIが倫理に反した形で使用されている場面を認識して、適切な処置を講じ、そうした試みに対抗することが可能になる。

この記事は海外Red Ventures発の記事を朝日インタラクティブが日本向けに編集したものです。
https://japan.zdnet.com/article/35209338/

当社の編集部は、IT業界に豊富な知識と経験を持つエキスパートから構成されています。オフショア開発やITに関連するトピックについて深い理解を持ち、最新のトレンドや技術の動向をご提供いたします。ぜひご参考になってください。






